Reverse Engineering NFSU2 Part 1 - Basic Structure
Need for Speed Underground 2 is one of my all time favorites. For a good portion of my childhood, it had me convinced spinners and underglow neons were the coolest thing you could do to a car (I get wiser with time, eventually). I took to trying to extract the assets from it, my hope being to mod the beautifully low poly city of Bayview.
When playing around in the games installation directory, I noticed all the cars had a file called “Geometry.bin.” Since I wanted to get into the game’s geometry, starting with the cars seemed like a good place to get my feet wet (even though the city mesh is the end goal). Here’s what I first saw:
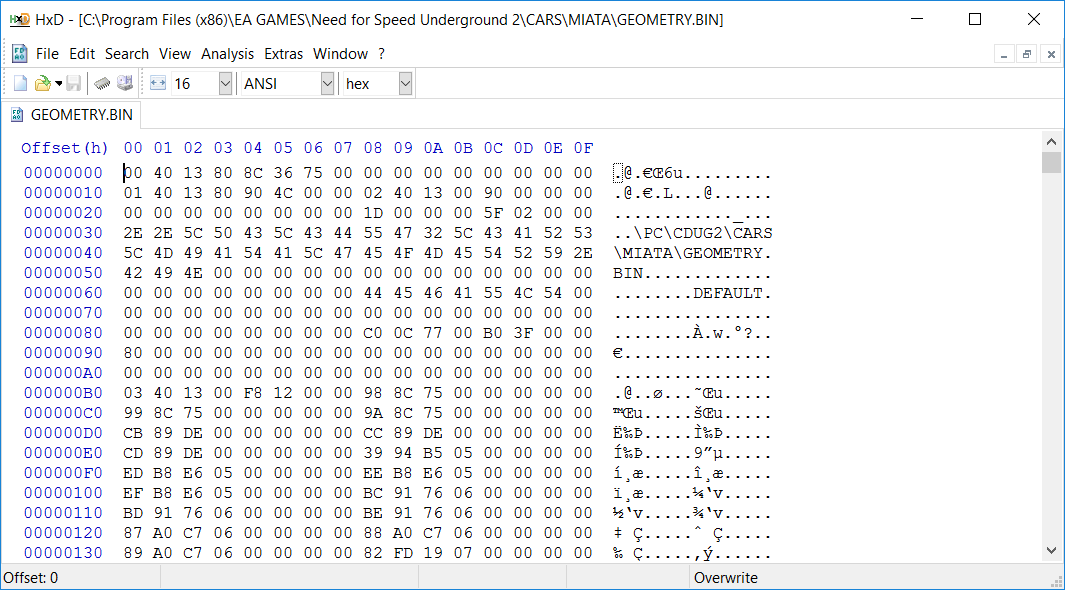
If you’re not familiar with hex editors, here’s the gist of it: The numbers you see on the screen are in hexadecimal, base 16 (instead of base 10). Hexadecimal digits go from 0-9 and then A-F to make 16 digits. Counting in hex goes like this:
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 1A, 1B, 1C …
Two hexadecimal digits can represent numbers from 0 to 255, the same range as 8 bits of a binary number (one byte). In the middle of the hex editor you see a whole bunch of 2 digit hex numbers. Each of these is a single byte.
On the right you see the same bytes of the file, only interpreted as ascii text. In ascii, characters are mapped to one byte numbers, but not all numbers represent a character. As a result, most of what you see on the ascii pane of the window is just dots, meaning invalid or unprintable ascii characters. If there is text in the file however, it is plainly readable (Note: there are many more complicated character sets out there, but most use the ascii mappings for common letters, numbers, and symbols, so you will still be able to see other text encodings in the ascii pane).
A note on notation: Hex numbers are often written with “0x” in front of them, so they don’t get confused with binary. So don’t be alarmerd if instead of writing 40 (hex) for a number, I write “0x40.” It just means it is hexadecimal.
Now on to the actual file. Often the first few bytes of a file are a signature confirming its file type. For example, a PNG file might start with “89 50 4E 47” which is “%JPG” in ascii. I tried googling the start of this file, however, and “00 40 13 80” didn’t yield any results. A little scanning with my eyes showed a pattern though–not many bytes later we see “01 40 13 80,” and later “02 40 13 80.” These are really big numbers to start counting with, so rather than indexes or sizes, I figured they are some sort of enumerated heading.
When programming to output a file, you will likely want to have different sections. You might give each section some unique header, like BE EF 11 01 in order to distinguish them. So you write code like the following:enum FileSections {
FILE_START = 0xBEEF1100,
FILE_META_DATA = 0xBEEF1101,
FILE_COLOR_DATA = 0xBEEF1102,
FILE_SOUND_DATA = 0xBEEF1103
}
The header enums don’t just start out at 0 because you want them to be obvious. Anyway, let’s just suppose for now 00 40 13 80 is some unknown section header. Now, we’re interested in the next four bytes: 8C 36 75 00. After scratching my head for a while, I realized this represents an integer that is suspiciously close to the number of bytes of the file (but not exactly). Note that in hexadecimal, 8C 36 75 00 is written as 0075368C. Virtually all PC processors use little endian numbers. In little endian, the bytes in a number are in reverse order. So for a two byte number, the bytes 12 34 actually represent the number 3412 in hex (notice that the bytes change order but the digits in bytes do not). Anyway, 8C 36 75 00 (hex, little endian) => 0x0075368C => 7,681,676 (decimal). And this file just happens to be 7.7 MB. What a coincidence?
It gets so much better though. Look at 02 40 13 00. It has 00 00 00 90 following it. A little while later we see 03 40 13 00. Between 02 40 13 00 00 00 00 90 and 03 40 13 00, there is presumably some sort of data. This data, we can find by highlighting it, is 144 bytes long. And 144 is 0x90 in hexadecimal. See the pattern! The format is like this:
Header (4 bytes)
Data length (4 byte integer)
Data (length = Data length)
But wait, at the first section header we saw the file size! Well, it turns out sections can be nested in these NFS asset files. We have sections within file sections. File section inception!!! Sections all the way down!
This sort of structure makes a lot of sense. Scanning a file one byte at a time for what you want would waste a lot of CPU cycles. Instead, we have a big tree structure in front of us that we can navigate quickly.
A lot more staring at the patterns of the file reveals more about this file structure. The file sections that have subsections all have a header ending in 80. So 01 40 13 80 has sections inside it, but 02 40 13 00 does not. Furthermore, the sections with child sections don’t seem to have data of their own, their contents are entirely made of other sections, and sometimes a few zeroes here and there to pad the sections out to round numbers.
Better yet, the zeros themselves appear to be valid sections. For example, consider 00 00 00 00 00 00 00 00. If we consider 00 00 00 00 to be a valid section header, then the next four bytes represent a data length for the padding section of zero. Sure enough, the next section starts immediately afterward. My theory was confirmed when I saw 00 00 00 00 00 00 00 04 00 00 00 00 later on. You can work that one out yourself.
I wrote a program to display the section tree I described. Notice by the scrollbar that this file has a pretty decent sized tree.
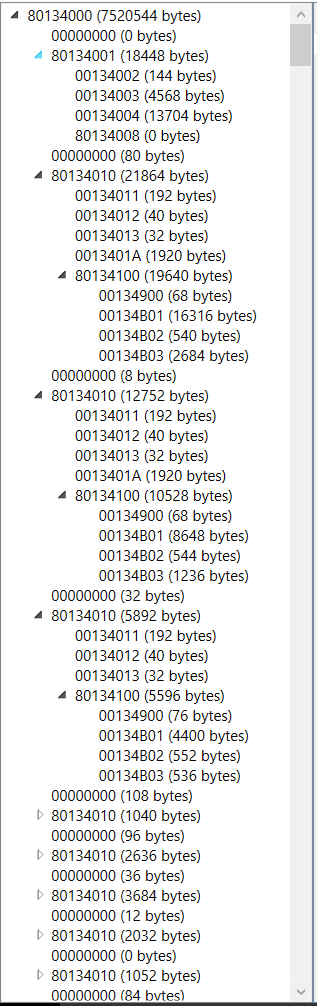
Cool, huh? Now that we see the structure, we have these nice bite size chunks that we can start to digest. We just need to know which one to start with. That’s next.